

23.04.2024
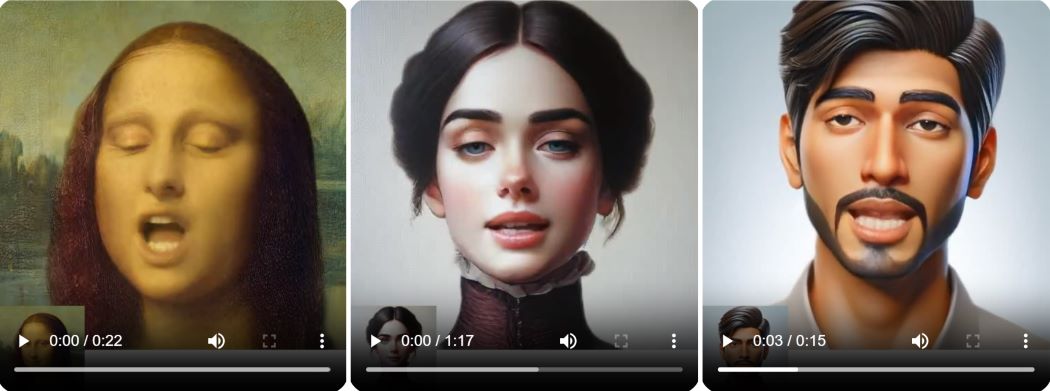
Корпорация Microsoft представила новую нейросеть VASA-1, которая может создавать видео на основе одного изображения. Для использования нужно предоставить картинку и аудиодорожку, после этого алгоритм сгенерирует говорящего человека с естественной мимикой и широким спектром эмоций. В примере, представленном компанией, заговорила, в том числе, Мона Лиза, сообщает Kommersant.
Главным отличием нейросети разработчики назвали целостную модель генерации движений головы и лицевой мимики. Согласно их подсчетам, новая нейросеть значительно превосходит ранее представленные аналоги. Видео доступно в разрешении 512 х 512 с частотой 40 кадров в секунду, есть небольшая начальная задержка.
“Первая модель VASA-1 способна не только воспроизводить движения губ, которые точно синхронизированы со звуком, но и передавать широкий спектр оттенков лица и естественные движения головы, которые способствуют восприятию подлинности и живости. Основные инновации включают в себя целостную динамику лица и генерацию движений головы, а также создание выразительного выражения лица с помощью видеороликов”, – говорится в заявлении компании.
В компании считают, что нейросеть поможет в создании реалистичных аватаров, имитирующих поведение человека во время разговора, однако не планируют в ближайшее время выпускать продукт на рынок из-за опасений, что он будет использоваться мошенниками для создания дипфейк-видео.
Иллюстрации и видео: microsoft.com












